
It seems naive to think that one equation underlies all of life. But nature confounds. There is such an equation and it goes by the name of the replicator equation. The replicator equation is a simple equation to model the way organisms adapt to their environment. Darwin taught us that life evolves by natural selection. But he didn’t tell us how organisms, from bacteria to humans, learn to figure out what traits or behaviors are best for them. The missing link is learning. Remarkably, as we shall see, practically all form of learning – from trial and error, to statistical learning and imitation, reduces to particular versions of the replicator equation, implying that something akin to a universal biological law exists in nature as far as adaption goes. This is a beautiful result which deserves to be more widely known, and is the reason why I am sharing this post.
Note to readers: this post is moderately technical. You can stop reading here, happy just to know that a certain mathematical unity underlies the extraordinary diversity of life on Earth, or continue with the discussion below for a more structured analysis in the format of a short tutorial. I have tried to keep the discussion succinct and accessible to a wide audience. In particular, no knowledge of math beyond high school algebra is assumed.
A Few Definitions
We will start by defining some terms. An allele (or “type) is the specific form of a gene. Genes are responsible for the expression of traits such as hair color. Alleles are responsible for variations in the way the trait is expressed (e.g., blondes, brunettes, redheads etc.). Genome is the complete set of genes and genetic material (DNA) in an organism. Scientists who study adaptation are interested in the time evolution of the distribution of genome structures in the population as influenced by factors internal and external to the organism.
The most general continuous selection equation describing how the distribution of genomes in the population evolves is the following:
![\displaystyle \dot{x_i} = x_i [(f_i(x) - m(x)], \qquad m(x) = \sum_{j=1}^{n} x_j f_j(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdot%7Bx_i%7D+%3D+x_i+%5B%28f_i%28x%29+-+m%28x%29%5D%2C++%5Cqquad+m%28x%29+%3D+%5Csum_%7Bj%3D1%7D%5E%7Bn%7D+x_j+f_j%28x%29++&bg=ffffff&fg=3a3a3a&s=0&c=20201002)
where ![\displaystyle x_i \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+x_i+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=3a3a3a&s=0&c=20201002)



The “x dot” on the left hand side of this equation denotes the rate of change (or derivative) of x with time. A positive x dot reflects an increasing frequency of a type and implies a higher than average value fitness for a given type in the genome distribution.
Darwin’s brilliant idea is that organisms adapt by the process of natural selection. That is, over time, they somehow are able to select traits that contribute positively to survival. Mathematicians have elegantly modeled this process using information-theoretic concepts from communications science, in particular concepts like entropy introduced by the “father of modern communications theory”, Claude Shannon in the 1950s. This is the first hint that the formal analysis of biological adaptation cuts across seemingly unrelated fields. Without going into the details, the idea is that as populations evolve, they increase the information they share with their environments, and decrease idiosyncratic information (i.e., they move away from statistical independence). Said differently, the dynamics of adaption favors decreased entropy or uncertainty.
The analogy between natural selection and information theory is is beautiful one, but it is silent on how organism go about extracting information from their environments. The missing link is learning. Organisms learn to adapt in many interesting ways. I will describe only two – statistical (Bayesian) learning and learning by imitation just to give a flavor of how diverse learning methods are modeled mathematically. As it turns out, we have the pleasing result that the dynamics of these learning modes also reduce to the basic replicator equation, demonstrating the existence of a unifying biological law of adaptation, the equivalent of the much hoped-for “Theory of Everything” in physics.
Bayes Rule (Statistical Learning)
In 1763, the Reverend Thomas Bayes’s posthumous paper, “An Essay towards Solving a Problem in the Doctrine of Changes” was published in the Philosophical Transactions of the Royal Society. The paper presented a new way to calculate probabilities with minimal knowledge of an event. The idea is to start with n educated guess (known as the prior probability of the event), then update this successively to a posterior probability after collecting more information about the likelihood of that event.
Bayes’s Rule is the engine behind what we now call Bayesian updating. When appropriately written, it reveals as a mathematical way of encoding adaptation. Note that whereas we think of adaptation in terms of the differential success of organisms, Bayesian updating treats adaptation as the differential success of hypotheses.
The basic updating equation for a hypothesis X is:
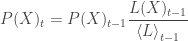
where the change in probability is delivered around the highest likelihood 
Let 

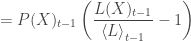

Now imagine time shrinks to the smallest unit of measurement (i.e., moving from discrete to continuous time). In continuous time, the evolution of the probability distribution reduces to the simplest form of the replicator equation:

Bayesian learning therefore can be viewed as a mechanism for Darwinian adaptation.
Learning by Imitation
Organisms also learn by imitating the behaviour of others. After sufficient time, the most dominant behaviour will be the one most frequently imitated. As with Bayesian learning, imitative learning can be described by mathematics.
Let 
![\displaystyle f_{ij} = [(R \mathbf{g})_i - (R \mathbf{g})_j]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_%7Bij%7D+%3D+%5B%28R+%5Cmathbf%7Bg%7D%29_i+-+%28R+%5Cmathbf%7Bg%7D%29_j%5D++&bg=ffffff&fg=3a3a3a&s=0&c=20201002)
where R is the reward matrix and g is the vector of strategic frequencies (think of this vector as the genotype or genetic constitution of an individual). Since lower payoffs are not imitated, 
The population of individuals will evolve in time according to a learning dynamic that reduces to another version of the Replication Equation:

![= \displaystyle g_i \sum_{j} [(R \mathbf{g})_i - (R \mathbf{g})_j ]g_j](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+g_i+%5Csum_%7Bj%7D+%5B%28R+%5Cmathbf%7Bg%7D%29_i+-+%28R+%5Cmathbf%7Bg%7D%29_j+%5Dg_j+&bg=ffffff&fg=3a3a3a&s=0&c=20201002)
![=\displaystyle g_i[ (R \mathbf{g})_i - \mathbf{g} R \mathbf{g}]](https://s0.wp.com/latex.php?latex=%3D%5Cdisplaystyle+g_i%5B+%28R+%5Cmathbf%7Bg%7D%29_i+-+%5Cmathbf%7Bg%7D+R+%5Cmathbf%7Bg%7D%5D+&bg=ffffff&fg=3a3a3a&s=0&c=20201002)
This last expression has the same form as the fundamental replicator equation. Thus, adaptive imitation, like Bayesian learning, follows a common dynamic pattern.
In Closing
There are other forms of learning. For example, there is reinforcement learning, where given time, correct (rewarded) behaviour becomes more probable and incorrect behaviour less probable. It can be proved that this type of learning, too, has the signature of the fundamental replicator equation. One might go so far as to say that the replicator equation underwrites all of life in the universe and that the mathematics of adaptive learning is a form of “biological algorithm” common to all life forms.
Further study
Hofbauer, J., and K. Sigmund (1998), Evolutionary Games and Population Dynamics, New York: Cambridge University Press.
Krakauer, D. (2011), “Darwinian demons, evolutionary complexity and information maximization”, Chaos, volume 21-037110, pp. 1-12.