In my previous post, (“Brilliant Minds: John von Neumann”), I reviewed a new book about the legendary mathematics genius, John von Neumann who played a starring role in the development of the modern computer as well as the atomic bomb during the Second World War. Von Neumann was also a co-inventor of Monte Carlo (MC) simulation, a computer-intensive technique for drawing random variables to model phenomena that are highly uncertain. MC simulations are now widely used in various scientific disciplines such as weather forecasting, engineering, physics and finance.
It is difficult to appreciate the power of MC simulations without working through an in-depth example. So in today’s post, I will provide a detailed illustration of how MC simulation is used to answer complex questions. My illustration is drawn from finance, and concerns portfolio risk management. To manage risk, investors must know how to measure it. Also, since risk is the possibility of experiencing adverse outcomes in the future, the future must be simulated. I will illustrate how this can be done with the help of a model that links risk or volatility to returns. That model is known as GARCH, which stands for Generalized Autoregressive Conditional Heteroskedasticity. Despite its formidable name, the basic idea behind the GARCH model is easy to grasp as will be apparent shortly. The GARCH model was pioneered by Robert Engle of New York University in the 1980s. For his contribution, Engle won the Nobel Prize in Economics in 2003. I will combine the GARCH model with MC simulation to forecast various intuitive measures of risk in the context of stock investments. I will refer to this combination as the GARCH-MC model. I hope to show you that the math behind it is both compelling and beautiful.

Robert F. Engle III (b. 1942). Professor of Finance at New York University, Nobel Prize in Economics, 2003 “for methods of analyzing economic time series with time-varying volatility.”
CAUTION – in the rest of this post, I will develop the GARCH-MC model step by step. The discussion will will be somewhat technical. If you love math, great – you are encouraged to follow each step through to see the beauty of the application. If you are not so math inclined, stay with me – you may want to skim through the equations to have a feel of what the story is about. Throughout the discussion, intuitive explanations of the key steps are given to help you along.
Let us begin.
Risk is Not a Dirty Word
Imagine an investor who owns a portfolio of stocks. His investment horizon may be a week, a month, or years. Along the way, he is likely to experience a roller-coaster ride as the stock market goes up and down. I assume the investor is risk-averse, i.e., he hates losing money. Yet losing money is part of the “game” of investing in the stock market, or for that matter, any risky asset.
My focus in on the type of risk that terrifies most investors: tail risk. The left-hand side of a returns distribution contains far-out regions where out-sized losses occur. Although this region of the left tail is small, when they occur, they can leave an investor totally devastated, financially as well as emotionally. I am mainly interested in quantifying the probability of such left-tail risk. The GARCH-MC technique allows me to do that. Before I proceed, I need to define a few standard measures of financial risk.
The ABCs of Financial Risk
Finance experts define risk in a number of ways. These risk measures fall into two broad categories that capture symmetric risk and tail risk respectively.
Symmetric risk measures quantify the dispersion of returns around the central point of the distribution, namely the mean. Two common and related symmetric risk measures are the standard deviation (also known as volatility in the finance literature) and variance, which is the square of the standard deviation. The more dispersed an asset’s returns are around the mean, the riskier is that asset according to these symmetric risk measures. This is because a wider spread entails a higher probability of bad outcomes – those returns that fall into the left side of the distribution – as shown in the following diagram.

Symmetrical risk measures are popular because they simply the math. However, they don’t tell us the probability of disastrous outcomes that occur in extreme regions of the left tail. Experts therefore turn to explicit measures of left tail risk. Two widely used measures of left-tail risk are Value-at-Risk (VAR) and Expected Shortfall Risk (ES). They are explained below.
Quantifying Tail Risk
I will use the letter K to denote an investment period. K may be as short as one day, or it could span longer periods. So, for a one-year time horizon, K is 365 days, for a ten-year horizon, it is 3,650 days and so on. K >> 1 day is my focus.
Let t denote today. The K-day VAR calculated today quantifies the risk going forward from tomorrow (day t+1) to day t+K. It can be written as follows:

where 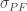
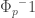
The VAR answers the following question: what loss is such that it will only be exceeded 100p of the time, where p denotes probability. If p is 0.05, then 100p is 5% and the 100p percent VAR is the cutoff value of the portfolio’s return such as there is at most 5% probability of exceeding that value. When the cutoff is on the left tail of the returns distribution, we attach a negative sign to the VAR to indicate that we are talking about losses. Note that VAR is always measured over a specified number of days. Looking at the above equation, what it says is that the K-day VAR is simply the square root of K times the 1-day VAR calculated on day t. The latter in turn is equal to minus 
The negative VAR only concerns the probability of losses exceeding a threshold. It does not tell us the magnitude of these losses, which is what most investors care about. To compute that, we use the expected shortfall risk measure (ES). Mathematically, the K-day ES is defined as:

The K-day ES has a pleasing symmetry with the K-day VAR, it being the square root of K times the 1-day ES where the latter is the average or expected loss encountered when returns are worst than the VAR:

Although neither volatility nor variance appears in the equations for VAR or ES, it doesn’t mean they have nothing to do with tail risk. This is because, as I mentioned earlier, the more widely dispersed returns are, the greater the potential tail risk. Thus, if we want to simulate future VAR or ES, we need to simulate the distribution of future returns linked to a model of volatility or variance. This is where GARCH comes in.
The GARCH model pioneered by Engle and other researchers capture a curious but pervasive feature of many asset markets, including the stock market. This feature refers to the tendency for returns volatility measured at daily intervals to cluster over days. Another way of describing volatility clustering is to say that days with high returns tend to be followed by more days with high returns and days with low returns tend to be followed by days with low returns. This feature is most pronounced when returns are measured daily, although weaker clustering effects are also found in weekly returns. To picture volatility clustering, have a look at the figure below which plots daily returns of the S&P 500 index over a 10-year period from Jan 2001 to Dec 2010.

The circled periods are days where high returns tend to be followed by more days of high returns. The rest of the periods are mostly days of low returns that tend to be followed by days of low returns. This clustering of daily absolute returns is exactly what the GARCH model capture. How it does so is explained in the next section.
Monte Carlo Meets the Greeks
The following pair of equations define the simplest GARCH model, the so-called GARCH(1,1):

The first equation model returns. It says that the returns on day t+1 is equal to a product of its volatility on day t+1 and the standard normal distribution, denoted by N(0,1). The second equation is the heart of the GARCH(1,1) model. It says that to forecast tomorrow’s variance, simply add today’s squared return to today’s variance and a constant term. The constant term, and the two coefficients (alpha and beta) can be easily estimated from data. For statistical reasons, alpha and beta added together must be positive but cannot exceed one. If the sum is close to one, volatility clustering occurs. If the sum is far below one, then volatility has no “memory”. Empirically, daily returns of stocks, currencies and commodities tend to show strong evidence of volatility clustering.
The above pair of equations tells us that if we can model volatility accurately (using GARCH), then by the first equation, we can also forecast returns. The reverse is also true; if we can simulate future volatility, then we can insert this forecast into the first equation to simulate future returns. This interrelationships between returns level and returns volatility is the basis of the GARCH-MC simulation procedure which I will now elaborate.
Using random number generators (standard in most quantitative software packages), we can generate a set of artificial or pseudo random numbers drawn from the standard normal distribution:

where MC denotes the number of draws (typically large, for example 10,000). From these random numbers, we can calculate a set of hypothetical returns for tomorrow:

Given these hypothetical returns, we can update the variance to get a set of hypothetical variances for the day after tomorrow, t+2 as follows:

Next, we draw another set of MC random numbers from the N(0,1) distribution:

From this set, we can calculate the hypothetical return on day t+2 as:

and the update the variance using

If we keep repeating this process up to MC times, we will get the following sequence of simulated future returns and variances (read row-wise):

where each row corresponds to a Monte Carlo simulation path, which branches out from the first day variance 

If we collect these MC hypothetical K-day returns in a set

then we can obtain the K-day value-ask-risk (VAR) simply by calculating the 100pth percentile as follows:

Once again, the VAR is the 100p percentile of the portfolio, or more exactly, it is the value of the portfolio such that there is a 100p% chance that the portfolio has lower returns than this threshold.
Like the VAR, we can compute the expected shortfall risk (ES) at different horizons using the following equation:

where the indicator value 1(.) takes the value 1 if the argument is true and zero otherwise.
End of application!
Let’s recap. We have applied Monte Carlo simulations to generate fictitious sequences of returns and volatility which are then fed into the VAR and ES equations to get summary measures of risk, either value-at-risk or expected shortfall risk. Throughout, we have used the GARCH(1,1) model as the model to forecast volatility. Apart from its elegant simplicity, this model is truly conditional in nature – tomorrow’s volatility forecast is built on today’s inputs which are already known, or simulated (as we have done). Armed with risk measures like the K-period VAR or better, the K-period ES, investors no longer have to helplessly ‘grope in the dark’, not knowing how the future will pan out for their investment. They now have numbers to guide their investment decisions, albeit numbers that are dependent on the assumptions of the GARCH model being the right one, and that returns conform to the normal distribution. More sophisticated models that relax these assumptions are available at the frontier of modern finance, but let’s leave these to the experts!
Hands-on with the GARCH-MC Model
To get a better idea of how the model works using real data, click on the following spreadsheet which presents the data (daily prices and log returns) of the S&P 500 index over 10 years, the estimated coefficients of the GARCH(1,1) model, and a section which simulates future returns using the Monte Carlo method and then rank them from worst to best. The results are summarized in a scatter plot. The expected shortfall risk (ES) is also shown for the worst 5th, 10th and 20th percentiles of the simulated return distribution.